What do you do when you get a bunch of files like this from a zipfile?
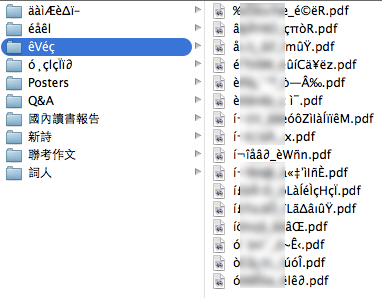
Back story: I have been tasked with collecting everybody’s Chinese assignments for this semester. I didn’t even do that part yet (I really should); first the girl who handled last semester’s assignments had to pass on the files she collected to me, and I unzipped the attachment to reveal these file names.
Well, I thought, no big deal, I
understand
Unicode (somewhat), I’ll just do something like decode them as
latin1 and re-encode them as UTF-8, right? Or maybe Big5? In fact, maybe
python-ftfy
will just automagically fix it for me; I’ve been waiting for a chance to
use that, like the dozens of other things on my GitHub star list…
I wish.
ftfy did nothing to the text. Also, UTF-8 was not high on my list because the filenames strongly suggested a double-byte encoding. By eyeballing the filenames and comparing them to the organized naming scheme of some other files that had, thankfully, survived the .zip intact, I noted that every Chinese character had replaced with two characters, while underscores had survived unscathed. It was a simple substitution cipher with a lot of crib text available. So that rules out the most common UTF-8, but it gives me a lot of information, so this can’t be hard, right?
One of the files that I knew belonged to me came out as such,
according to Python’s os.listdir:
'i\xcc\x81\xc2\xaci\xcc\x82a\xcc\x8aa\xcc\x82\xe2\x88\x82_e\xcc\x80Wn\xcc\x83n.pdf'
After codecs.decode(_, 'utf_8') we get:
u'i\u0301\xaci\u0302a\u030aa\u0302\u2202_e\u0300Wn\u0303n.pdf'
Attempt at UTF-8 rendition: í¬îåâ∂_èWñn.pdf
That’s really weird; those codepoints are kinda large, and there’s a
literal i at the start, and it doesn’t look at all like the
two-characters-for-one pattern we noticed from staring at the plaintext.
Oh, they’re using combining characters. How do we fix that?
Fumble, mumble, search. Oh, I want
unicodedata.normalize('NFC', _).
u'\xed\xac\xee\xe5\xe2\u2202_\xe8W\xf1n.pdf' Attempt at
UTF-8 rendition: í¬îåâ∂_èWñn.pdf
Although the byte sequences are totally different, they look the same, which is the point. holds up fist This… is… UNICODE!!!
Anyway, the code points in the normalized version make more sense.
Except for that conspicuous \u2202 or ∂, of
course. Indeed, although it looks promising, if we now try
e.g. codecs.encode(_, 'windows-1252') we get,
UnicodeEncodeError: 'charmap' codec can't encode character u'\u2202' in position 5: character maps to
One can get around this by passing a third argument to
encode to make it ignore or replace the invalid parts, but
the result of the first couple of codepoints, after further
pseudomagical decoding and encoding, is still nonsense. Alas.
I continued to try passing the filenames in and out of
codecs.encode and codecs.decode with various
combinations of utf_8 and latin_1 and
big5 and windows-1252, to no avail.
Then I did other stuff. Homework, college forms, writing a bilingual graduation song, talking to other dragons about 1994 video games, and did I mention I started taking driving lessons now? Yeah. That sort of thing.
Around that last thing, I asked the previous caretaker and learned
that the computer she collected these files had a Japanese locale. So I
added shift_jis and euc_jp to the mix, but
still nothing.
I later tried unzipping it with unzip from the
command-line — the results were even worse — as well as unzipping it
from a Windows computer — even worse than the command line.
So the problem remained, until…
The resolution is very anticlimactic; it took me half a week to think
of getting at the files programmatically straight from the zip archive,
instead of unzipping first. Python spat out half the file names from the
zip file as unicode and the other half as str.
From there it was easy guessing.
There were still three file names that failed, but they were easy to fix manually.
I’m not sure why I eventually decided to blog about this anymore, honestly. Especially compared to my 12 other drafts. Oops.
ETA: I thought this script would be a one-trick pony but, amazingly, I ended up using it again the day after, this time withBig5
after I copied some files to a Windows laptop, converted them to .pdf,
and sent them back in a .zip.
ETA2: This script came in handy again after I copied a zip file
to an Ubuntu desktop computer with an actual CD drive so I could burn
everything to a disc!