This challenge is a video of somebody’s messy desk, with what is apparently the audio from a Futurama clip. The desk is indeed extremely messy and full of things that aren’t particularly useful for us, but close examination reveals a QR code reflected in the globe in the middle.
The challenge is all about getting that QR code. After trying our best to clean up the image, we ended up with this:

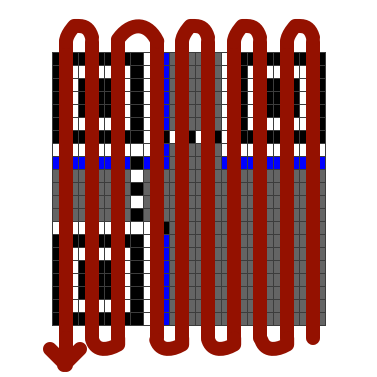
After rotating it tastefully, we spent a long time transcribing from this QR code to a Google Sheet as best we could. Some useful references were this post on deobfuscating a QR code for a bitcoin wallet and Thonky’s QR Code Tutorial, a step-by-step tutorial to producing a QR code featuring steps such as “Step 4: Understand Galois Field Arithmetic”. At some point, we realized we had transposed the entire thing, because our QR code was missing its Dark Module in its bottom-left and somebody had read a good Format Info string in reverse order without realizing. (The word “module” is the term for the smallest black-and-white blocks that make up QR codes; we don’t use the term “pixel” to avoid confusion, since QR codes will often be rendered on a screen with each module taking up many pixels.)
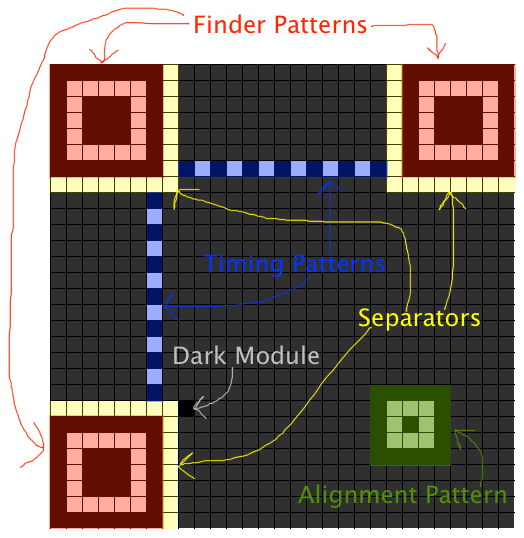
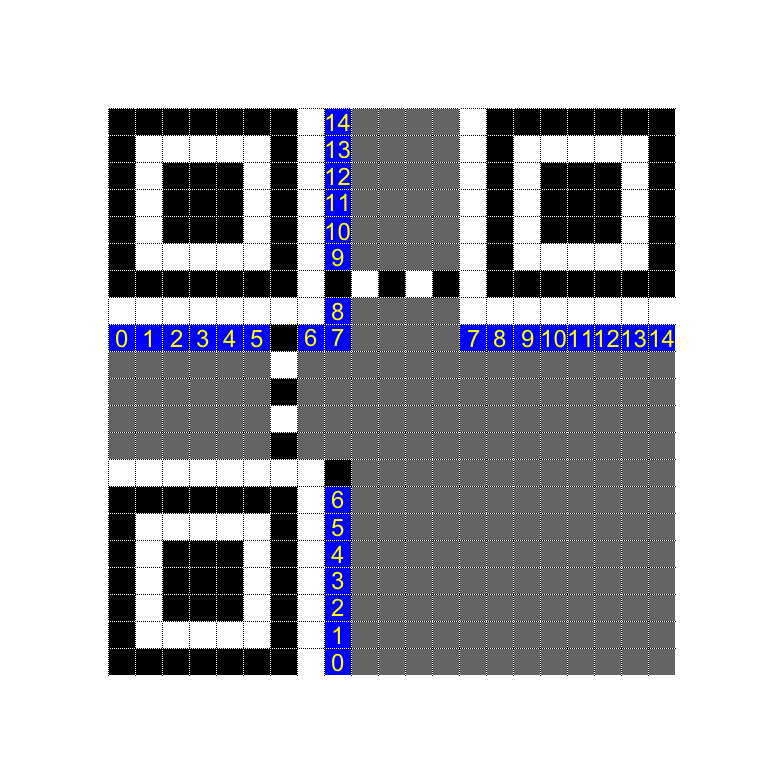
Counting the modules in our QR code told us that it was Version 2. (“Version” is the word for a size of a QR code; they start from Version 1 with 21×21 modules, and the side length increases in steps of 4.) Cross-referencing our blurry Format Info String against Format Version Tables indicated that it was most likely 011000001101000, which meant that the QR code used error correction level Q and mask pattern 1. Thus, we’d need to flip every even-indexed row of our QR code to get the original data back. With a little bit of spreadsheet magic, we set up our spreadsheet to apply the mask to the QR code automatically.
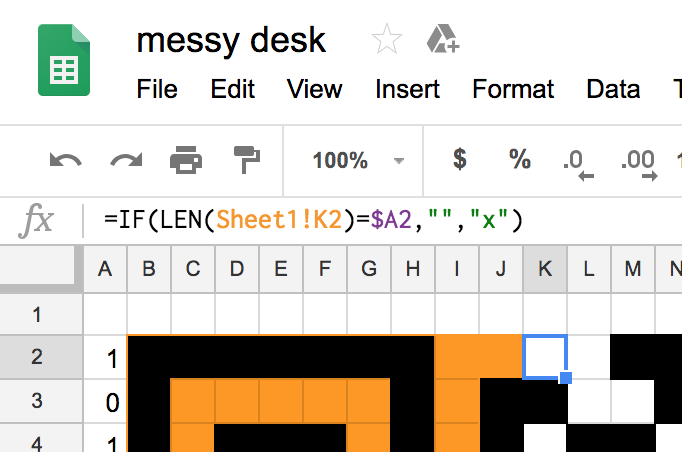
After the unmasking and reading up about the strange zig-zag
order in which modules
are placed on thonky.com, we could finally start reading off bits
from the lower-left corner, and applying our knowledge to reconstruct
the QR code by fixing bits in the bottom-right corner until our unmasked
QR code started with PCTF{. (Specifically whenever we found
a bit in our that was wrong, we went to the other sheet with the
transcribed QR code and flipped the modulle there, which would
automatically update the unmasked sheet.)
{kind=link}
{kind=link}
Soon, in accordance with the Data Encoding procedure, the first few bits of our unmasked QR code read:
0100 Byte Mode encoding
00010010 18-character message (?)
01010000 P
01000011 C
01010100 T
01000110 F
01111011 {In the small Version we’re working with, all error correction bytes are simply appended after all the raw data, so we could just read the raw message as the next 18 characters in the bitstream of the QR code without worrying about understanding the error correction.
Our very first attempt to continue reading and finagling everything
into ASCII range gave us something like PCTF{50gf8nVLH,Ng}.
Unfortunately our fixed-up QR code still wouldn’t scan. (According to netsuso’s
writeup, of Pandemic, their QR code scanned at this point, so
evidently our transcribed copy had more mistakes.) So we would need to
dig deeper.
The first thing I did was look more closely at the length field. We
weren’t sure if it was 18 or 19, but Step 4 of Data
Encoding shed some light on the matter. After the data is encoded,
it has to be padded with zero bits to a whole number of bytes, and then
padded with the magic pad bytes 11101100 00010001 one at a
time, repeating if necessary, to the right number of “raw data” bytes.
In our case, consulting the Error
Correction Code Words Table for Version 2 with error-correction
level Q, we knew that the total number of raw data bytes must be 22.
If the message length was 18, then after prepending the Byte Mode
indicator and the length, it would be 19 bytes and a nybble. So it would
have to have been padded with one nybble of zeroes followed by two magic
pad bytes, and the last raw data byte before error correction would be
00010001. On the other hand, if the message length were 19,
then after the mode indicator and length, it would be 20 bytes and a
nybble, so it would have to have been padded with one nybble of zeroes
followed by one magic pad byte, so the last byte would be
11101100.
I looked at our QR code, and without needing to fix any bits, I saw
that the last raw data byte (the 22nd byte from the start, the red
region below) was 11101100, and that it was even preceded
by a zero nybble, which was very strong evidence that the QR code
message was 19 characters long.

So I flipped the right bits, including the closing brace, until our
QR code reflected this. After playing with more modules that looked
ambiguous, I got the raw data bytes of our code to read something like
PCTF{z8gf8nWlH4fcY}. Due to the theme, I decided to hope
that the last few letters of the flag were “enhance”, so, squinting at
the image, I flipped more bits until it read
PCTF{z8gf8nenH4nce}. (Another hypothesis I had was that the
start would be zigzag or something similar since I had just
learned so much about the zigzag pattern of QR modules, but this was not
the case.) I was still engrossed trying to flip more bits to get better
English when another team member happened to retry scanning the QR code
I was working on and discovered that it worked, so we ended up with the
flag:
PCTF{z0oo0m_nh4nc3}