Advent of Code (briefly, “AoC”) is a series of 25 festive programming puzzles1 released daily December 1–25. Each puzzle has two parts, which use the same text input and are related; to solve a part, you submit the right output corresponding to the input on the website.
If you’re reading this, I suspect there’s a good chance you knew that already, but in case you’re new to Advent of Code, let me try to briefly explain why I like Advent of Code, from the perspective of somebody who’s spent a lot of their life so far doing programming competitions.2
- The event has a fantastic community surrounding it. I’m the most familiar with the subreddit, which is full of helpful people, interesting discussions, non-programming community games, and the occasional wonderfully, spectacularly overengineered solution to a puzzle; but I know there are also many smaller chatrooms and subcommunities focused on, say, specific timezones or programming languages.
- Another aspect is the unique two-part format of each puzzle. Even though they use the same input, you don’t get to see the second part until after you’ve solved the first one, a feature that Eric Wastl (AoC’s creator) has taken full advantage of in designing puzzles. The second part is often a surprising twist on the first part, which keeps you on your toes and challenges you to keep your code moderately general or refactorable in a way that I think almost no other programming challenges do. This sometimes even happens between days in a calendar, when a puzzle turns out to be about some model of computation you implemented two or five or ten days ago — hope you kept your code and remember how it works!
- Finally, AoC also has some non-rigorous puzzles that force you to use your intuition and “human intelligence”, either by interpreting the problem statement heuristically or writing code to let you explore the input. There are quite a few puzzles where it’s infeasible to write code that handles every step of obtaining the output from the input. The result is that Advent of Code can feature quite a few challenges that I’ve found particularly compelling because I think they simply could not be posed on any other contest platform.3
These are the things that make AoC stand out to me, but it also does a lot of other things well — the challenges are fun, approachable, and varied even aside from their interrelations; there is a long, dramatic story tying everything together (although it’s an Excuse Plot if there ever was such a thing); and, although this is obviously subjective, I find the website’s minimalist-adjacent, terminal-esque aesthetic really charming (there is a lot of detail in 2019’s calendar… after you solve everything). I’ve only done the last two years of Advent of Code, but it really seems like a one-of-a-kind event to me.
Anyway, one particular feature Advent of Code has is a leaderboard, which you can get on by being one of the first 100 people worldwide to solve each puzzle. The competition is fierce — every year, thousands of people compete to get on the leaderboard. Near the start of AoC 2019, mcpower (reddit discussion) and Kevin Yap (reddit discussion) wrote some articles about how to do this, both of which are worth reading. I also thought about writing such an article and started a draft, but I didn’t get it anywhere close to publishable before AoC had concluded, at which point I assumed few people would be interested. But here it is now.
Meta
Before we get to that, however: as AoC’s creator wrote, getting on the leaderboard might not be the most suitable goal for everybody. There are lots of ways to do Advent of Code. If you ask me, the best one is whatever you think you’ll get the most out of. You could try it with a new or nontraditional programming language, or text editor, or keyboard layout. You could aim for something other than getting the answer as quickly as possible: maybe optimize your programs for speed, conciseness, readability, or some personal sense of aesthetics. To get a sense of the massive variety of approaches others have taken, you might scroll through the posts flaired with Upping the Ante in the subreddit.
Every now and then somebody posts on the subreddit that seeing how slow they are at Advent of Code compared to the people on the leaderboard makes them feel like a worse programmer. I would like to assure such people that this means nothing of the sort. On my first try on the very first part of AoC 2019, I was trying to write this code:
s = 0
for line in input_lines:
s += int(line) // 3 - 2
submit(1, s)Instead, I wrote this code:
s = 0
for line in input_lines:
s += int(line) // 3 - 2
submit(1, s)This was enough to prevent me from getting on the part 1 leaderboard. What a difference a tab makes!4 Getting on the leaderboard is affected as much by programming skill as it is by the tiniest of mistakes and mental lapses, the kind that everybody makes. Razor-thin differences in time can translate to massive swings in leaderboard placing. Not to mention, the programming skills that are relevant to solving Advent of Code puzzles quickly are fairly narrow and not all that reflective of general programming ability; I am nowhere close to the world’s best programmer.5 So I wouldn’t take anybody’s leaderboard position too seriously. With all that said, it’s pretty fun if you approach it with the right attitude.
This post is structured as more of a grab bag of suggestions, loosely in descending order of “efficiency” — earlier items improve your leaderboard chances more for the same amount of effort, in my opinion. Obviously, your mileage may vary.
Be free when puzzles are released
As silly as this is, it’s definitely the most important requirement if you want to have a chance of getting on the leaderboard, so I think it has to come first.
For most of December 2018 and the first half of December 2019, I was a college student on the east coast of the U.S., and doing AoC at midnight wasn’t a big deal. I started traveling halfway through December 2019 and did day 17 on a plane with incredibly fragile wi-fi that I had to pay for (6th/2nd).
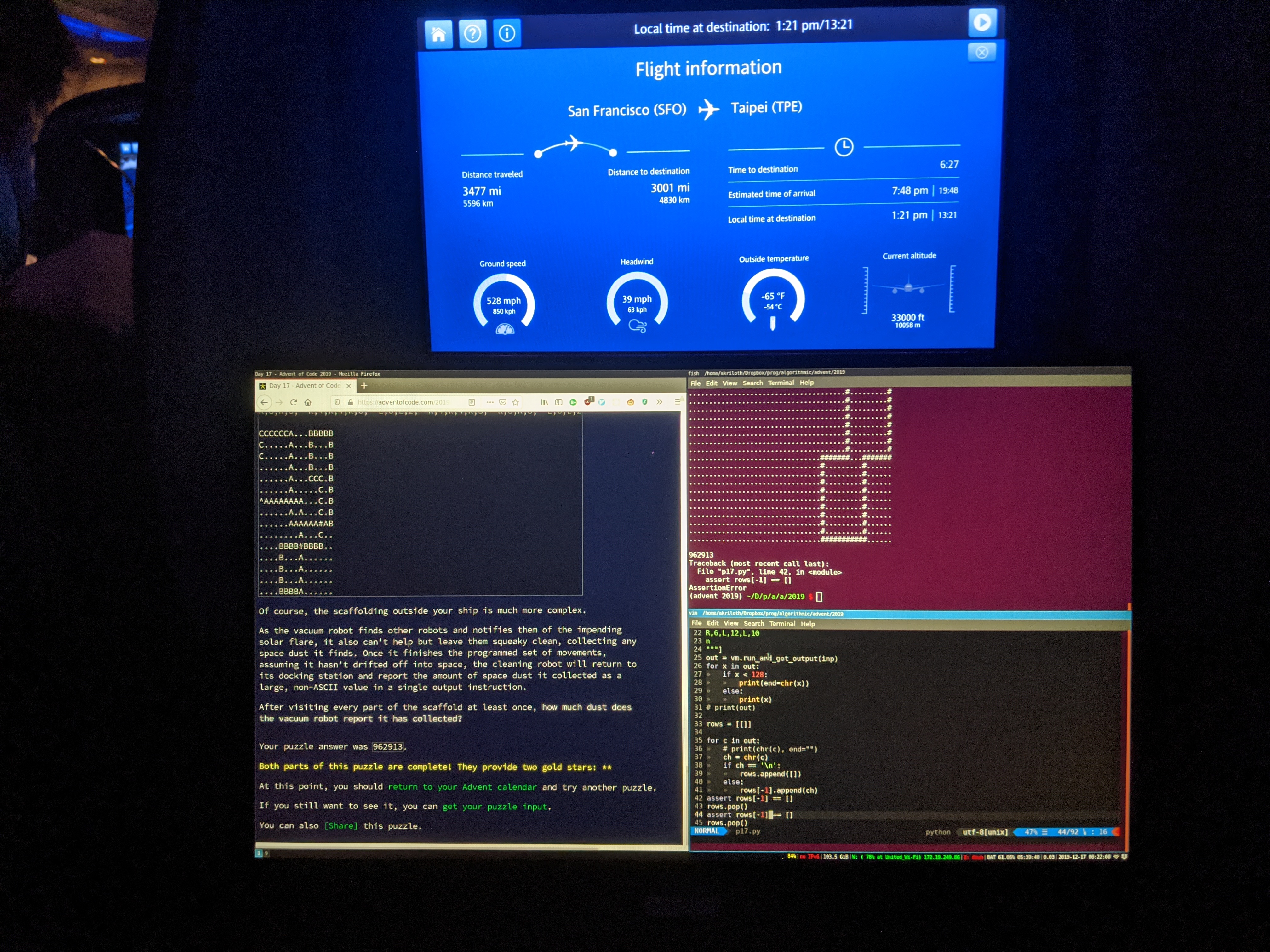
I did all the later days at 1pm local time, including discreetly doing day 22 from my phone, SSHed into a tmux session on an MIT server, while I was at a relative’s wedding (45th/24th).
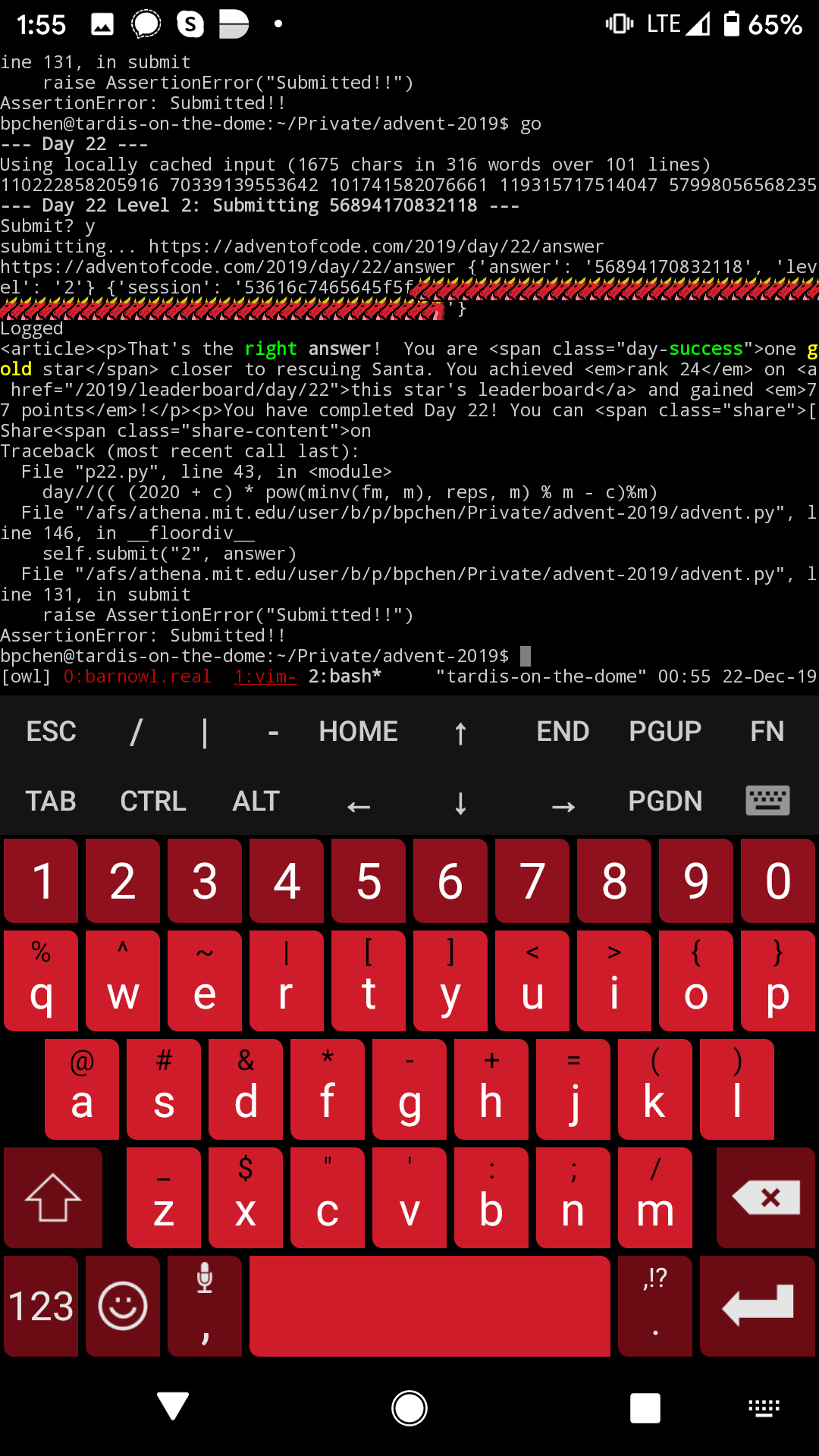
Knowing that those two days were coming up was why I expected to be less competitive than I was in 2018, but I guess I got lucky. I cannot recommend everybody go to the same lengths to do Advent of Code on time. You’ll have to decide for yourself whether it’s worth it.
Don’t write bugs
This sounds like facetious advice — arguably, software engineering would be trivial if you could just choose to not write bugs — but I do kind of mean it. Bugs are the single factor that will slow down your time-to-solve the most while still being relatively easy to fix. (“Not knowing how to solve the problem” will slow you down far more, of course, but fixing that tends to be a lot harder.)
A slightly more useful, less obvious way to phrase this advice, which is also the best advice I’ve ever gotten in competitive programming, is to make it hard for yourself to write bugs. The efficiency and conciseness of your code are both worth trading off (in moderation) in pursuit of this goal. When you write code, think of it as code that you’re handing off to yourself a few seconds or minutes in the future. Your future self will not have the clear memory of the code you’re writing that you do right now; they will be thinking about other things. You’re participating in an asynchronous research loop6, albeit one with pretty low stakes, fortunately.
I don’t have a step-by-step procedure for not writing bugs, because different programmers will be more likely to write different kinds of bugs and will need different strategies for avoiding them. But here are some possible implications, which are things I try to do, that could be a potential starting point:
Try to name your variables consistently — not just within a function or a source file, but across all your AoC solutions and solutions for similar programming challenges. The ideal scheme will allow you to mentally rederive the variables you named a few minutes ago from long-term memory or even instinct instead of looking back at your source code, and will let you predict the type and meaning of variables you’re working with from their names. For example: Whenever I do a binary search, my current lower and upper bounds are almost always
loandhi. Whenever possible I will index two-dimensional tables withr(row) andc(column), as opposed toxandy, which “go the other way” if the input is provided as a list of lines, as is common. I use the variableseena lot to collect a set of visited nodes or locations in a search.When you encounter a new or problem-specific concept, pick a name quickly and stick to it. In 2019 Day 20 part 2, for example, you have to search a “three-dimensional” space, where the third dimension of how inwards or outwards of a layer you’re on doesn’t have a precise name. I don’t think I even consciously thought the words “three-dimensional” before deciding to call that “coordinate”
z, which allowed me to assign unmistakeable names to a bunch of variables involving the concept. More interestingly, in my solution to 2019 Day 14 I referred to each (integer, chemical) pair as aningredient, each chemical as athing, and each reaction as arecipe. In hindsight, these names made no sense, especially considering that none of them appeared in the problem description, but they fit in my head and allowed me to distinguish their types more clearly than the actual problem’s words.Strive to avoid awkward indexing and opportunities for off-by-one errors. If a problem gives you indices for a one-indexed list or array, it’s often less bug-prone to create a list or array that’s one bigger than what you need and just not use index 0 of it, than to remember to subtract 1 every time you use a problem-provided index. You can also just use a dictionary or hash map. If you do want to convert to 0-based indexing, convert it in a single place as far as possible so you can then forget about it, most plausibly on the boundary of your program — right after reading input and right before writing output. Write both parts of that conversion code in one sweep before going to work on the rest of the solution, so there’s no chance of you converting in one direction but not the other.
More generally, learn to recognize the places you often write bugs, and stay alert or slow down when writing them. For me, I often find myself in scenarios where copy-pasting code is faster than refactoring the code into a loop, but it’s also riskier, so I try to reserve extra vigilance for those scenarios. It still doesn’t save me every single time, but I’m getting better at it.
If you have bugs, catch them early
An ounce of prevention is worth a pound of cure, but sometimes a pound of cure is your only option. Bugs happen. Catch them.
mcpower writes in bold, “don’t validate the input.” I agree with this in the sense that you shouldn’t be wasting any effort verifying promises made by the problem statement, because those promises will not be broken. However, you may wish to verify constraints derived from those promises, because your code might be broken, or because you might copy your code later into a position where those promises might no longer hold.
An example from 2019: Over multiple days, the AoC puzzles slowly introduced us to features in the “Intcode” computer, which used sequences of integers as instructions. One feature introduced in day 5 was that each instruction included three digits called the “parameter modes”, which could only be 0 or 1; furthermore, the last parameter mode in each instruction could never be 1. So you could choose not to read or validate the last parameter mode, just assuming it was 0, and successfully solve those two days’ puzzles. Nevertheless, asserting that the last parameter mode was 0 could be beneficial:
- Firstly, it might let you catch intermediate bugs faster, like if you had mistakenly parsed the parameter modes in reverse order.
- Secondly and more importantly, your assertion would have failed in Day 9, which introduced the digit 2 as an option for all parameter modes, reminding you to add support for it there instead of silently doing the wrong thing. I saw a few people bit by this bug on the subreddit.
This kind of issue is rare in non–Advent of Code challenges, which is why I think it’s particularly worth calling out. Sometimes a problem will allow you to make some correct, simplifying assumptions when first coding a solution, but the problem will invalidate those assumptions in part 2 or in a later day, which you can’t see until later.
When you know you have a bug but not where it is, there’s often a strategic choice between rereading your code to look for the bug and manually testing your code against a test case, either from the Advent of Code website or manually generated. The former is much faster if it succeeds, but less reliable, so it’s usually good to start there and switch to the latter after some time. Unfortunately I don’t have great advice for figuring out when to switch, but both are useful skills.
I will say that, if you do test things, make sure you’re testing them on the right input and are correct about what the expected output or behavior is. While doing 2019 Day 20 part 2, I sunk a bunch of time into testing my program on the second example and trying to figure out why it wasn’t terminating. I failed to realize that the problem said:
In the second example above, there is no path that brings you to ZZ at the outermost level.
Not terminating was actually the correct behavior for my program; I wasted a bunch of time debugging when there was nothing to debug. Don’t be like me.
Get comfortable with your language, standard library, and editor
People often suggest that, to code quickly, you should choose a concise programming language that you know well enough to write without looking stuff up. I don’t think either of those things are necessary, but the catch is that you still have to get code from your head into your computer anyway. Having an efficient editor and workflow, maybe with powerful autocomplete, heavy usage of macros, or particularly deep language integration, can compensate for using a more verbose programming language or one you’re less familiar with.
With that said, I use Python anyway, which I think is pretty popular on the leaderboard and fits both of the first two criteria for me. If you are also using Python, things I would suggest knowing from the base language and standard library:
- Obviously, know the basics like operators, control flow, and function definitions. Make sure you are deeply comfortable with tuples, lists, slices, packing/unpacking assignments and argument lists, list comprehensions and generator expressions. This includes their performance.
- Know most of the built-in functions and the operations on sequence types and on strings. The ones more related to types or metaprogramming probably won’t be too useful in Advent of Code, but almost everything else is helpful.
- Know how to use Counter, defaultdict, and deque from the collections library.
- Be familiar with itertools and re (regexes).
Equally importantly, know what you don’t know. If you’re not sure
what a function does exactly or what order its arguments go in, don’t
use it without looking it up. (To my future self: atan2’s arguments are
y, x in that order. Please.)
In any language, you should be good at editing half-abstracted
half-copy-pasted code, because often it will be faster to write than the
properly structured code with all the right abstractions. A common way
this arises is writing code for handling the four neighbors to a cell in
a square grid in some similar fashion. I am a lifelong Vimmer and find
features like repeat (.), macros (q and
@), and block visual mode (Ctrl-V)
particularly useful for this kind of thing, but most popular code
editors have facilities that can achieve similar effects. Try to learn
them.
g CTRL-A, inserting
around block visual mode…
Get comfortable with common algorithms and data structures
It’s tough for me to write this section because there’s no well-defined canon of what algorithms and data structures are “common”, in particular, “common enough to appear in Advent of Code”. Even if there were, since I’ve already spent years learning competitive programming to the college-level ICPC and beyond, which is way overkill, I would be pretty poorly-calibrated on what topics belong in the “common” anyway. But if I were to attempt to list some anyway, here are some things I think you must know how to use and do if you want a shot at solving every AoC problem by yourself:
- arrays and hash tables (well, their implementations in your favored programming language);
- recursion and backtracking;
- sorting (well, how to use your programming language’s
sortfunction) and binary search; - basic graph algorithms like DFS, BFS, and Dijkstra;
- basic dynamic programming;
- basic number theory, including modular arithmetic and GCDs/LCMs.
Things that I can remember being useful in past AoCs but that might not be strictly necessary:
- disjoint-set union;
- topological sorting;
- some heuristic search strategies like hill-climbing.
For those who want something more systematic than just a list of terms to Google, I would tentatively suggest the MIT 6.006 OCW course and/or some of the recommendations on Teach Yourself Computer Science. And practicing on past AoC problems is always good.
Build your own standard library
Some things you’ll do a lot in AoC probably won’t be in your programming language standard library because they’re not that broadly applicable. Particular examples include specific kinds of string parsing and functions for working with adjacent cells in a grid. If you can identify these recurring computations and prepare functions to perform them ahead of time, you’ll be that much faster when actually doing AoC live.
One example that stuck with me is when mcpower wrote:
The
ints(gets all integers from a string) function was used a lot - thanks again, mserrano!
This ints function takes a string, parses out all the
integers from it with a regex, and returns a list of those integers. I
did not look at other people’s standard libraries for a long time while
building my own, but incredibly, I had written a function with
identical behavior and name. That’s a testament to how
often this kind of string parsing is useful in AoC.
If you practice on past AoC problems, you should quickly get a sense of the kinds of utilities you might be useful. You can also find many Advent of Code utility libraries online, for example on the Awesome Advent of Code repository. I wouldn’t recommend copying anybody else’s standard library wholesale, because you want to be extremely comfortable with it and you won’t be able to turn to Google for help using it. However, it can be quite useful to look at them for inspiration and take the bits and pieces you think are useful.
This is not to mention the instances when concepts repeat and evolve between days. In my first year, 2018, I was surprised to see a small assembly language introduced in Day 16 become relevant again on Day 19 and then Day 21. Then in 2019, we had puzzles instructed us to work with Intcode programs on days 2, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, and 25. I have no idea what 2020’s calendar will bring, but cleaning up your code from previous days in case you need to reuse or modify it is probably not a bad idea.
Don’t be afraid to put yourself in the loop
This is one of the ways Advent of Code departs from traditional programming contests most significantly: instead of giving constraints on every input you get and expecting you to write a program that handles the fully general problem, including all corner cases, Advent of Code gives you a single test case that you have to handle.7
Firstly, this implies that if you want to be able to quickly assess
whether your algorithm is fast enough, you’ll have to analyze your input
yourself. For those of you coming from other programming competitions,
you won’t be able to just scan the problem description for an inequality
like “N ≤ 100,000” and estimate that Θ(N²) will be too slow but Θ(N log
N) will be fast enough; you’ll have to compute N yourself and then do
the estimation. In addition, occasionally, your input will be a special
case is significantly easier than the general problem. 2019 Day 16 Part 2 was a
somewhat infamous case of this, where the size of the first seven digits
of people’s input signals made the problem much easier (extended reddit
discussion). 2018 Day
20 (both parts) was another case where the puzzle input’s structure
was less obvious — a lot of solutions on the solution
megathread give the wrong output for even very simple inputs like
^(N|)E$ or ^(N|ENW)$, but still succeeded on
the actual puzzle input because it was generated to have such nice
structure (extended reddit
discussion).8 These situations can be frustrating
when you feel like many people got onto the leaderboard ahead of you
without “truly solving” the problem, and I can imagine also being pretty
annoyed if I had entirely missed any leaderboard due to one of these
situations, but I don’t think there’s a clear line between them and the
kind of puzzles using hyperspecifically-crafted inputs I think make AoC
uniquely compelling, so I’ve accepted that it just comes with the
territory.
A further implication is that, when it comes time to actually solve the challenge and submit an answer, your program does not have to do all the work of getting from input to output for you. You can use your favorite text editor or ocular organs to manually preprocess the input, postprocess the output, or both. There are some challenges where the need for these tactics is obvious, e.g. 2019 Day 8 and Day 11 and 2018 day 10.9 All of those problems involved drawing 2D graphics of some alphanumeric characters and then submitting those characters as the answer. It’s relatively easy to write a program that would render the graphic, but much more difficult and not at all worth it to write a program to parse those graphics into the characters that are the ultimate answer. 2019 Day 17 Part 2 (solution thread) is another example. The problem has a couple moving parts, but there’s a particular subtask of breaking a path into a main routine and functions that’s really hard to do programmatically with any generality. However, the path is so short that manually breaking it down is feasible.
Some less obvious examples where I personally got some mileage out of manual preprocessing, but wouldn’t expect everybody to:
- On 2018 Day 24, I didn’t want to parse the input programmatically, so I manually preprocessed it in Vim. You can see the preprocessed input inline in the code I submitted to reddit.
- On 2019 Day 20,
under time pressure, I couldn’t think of a simple way to tell whether a
labeled spot was an inner connection or an outer connection, so I
manually replaced all the inner
.connections in the input with a different character and tested that.
The advantage of preprocessing input in a text editor is that the feedback loop is almost instantaneous: you’re always staring at the result of all the preprocessing you’ve done so far. The disadvantage is of course that it’s less reliably repeatable. If you later have to preprocess sample inputs in the same manner to test your code on them, you might find that you’ve slowed yourself down on net.
Yet another way you can put yourself in the loop is by using output from early versions of the program to inform later versions. For example, say you’re trying to count something in a loop, but you’re not quite sure if your count is off by 1 from what the puzzle is asking for. Instead of carefully reasoning through how your loop count relates to the problem statement, it may be faster to run your code on a sample input, see how far off your answer is, and copy the difference back in to your program. Or, if your program is trying to optimize something over a large search space but is too slow, you can keep a copy of it running and printing information while making the code more efficient or adding features to prune the search space. When the new version of your code is ready, you can initialize it with the running copy’s intermediate state or best result to speed it up. Regardless of exact implementation, though, the overarching principle is the same: The entity that has to convert your AoC input into the correct output isn’t the program you’re writing, but the computational system comprising you, the program you’re writing, and any other tools you have at your disposal. Don’t squander any part of that system.
Go fast
Cut whatever corners you need to get your code out faster. Write hacks. Copy-paste code. Hardcode constants. Mutate data unreservedly. Use exceptions for control flow. Coerce booleans to integers and use them as indexes. Represent data as strings even when you definitely shouldn’t. Be proud.
Beware that cutting corners often produces more opportunities for bugs to occur. If whatever you’re doing isn’t considered best practices, there’s probably a reason for that, and often it’s precisely because it’s more likely to produce buggy code, which can easily slow you down by more than the amount of time you saved. That’s why I put this section so late in the list of suggestions and so far after the “Don’t write bugs” section. But if you’re 100% confident about how your hacky code will work, or if you think the “best practices” alternative to your hacky approach is significantly more verbose, don’t hesitate.
Read the problem quickly
To be honest, I’m not sure if I can faithfully describe my strategy for reading AoC problems — it just goes by so quickly. But in broad strokes, I think I start by aggressively jumping back and forth between the prose and examples, whichever one seems easier to understand, until I have the big picture of what’s going on. After that, I read through the prose again more systematically, skimming “pure flavor” things that don’t look relevant, to make my understanding more precise and make sure I’ve seen any gotchas or corner cases.
If you read a few AoC problems from this year or a previous one, you should start to develop an intuition for what things are “pure flavor” and what things are problem-relevant, which is really useful for going fast. But it can also lead you astray, especially for some of the “squishier” problems that involve non-rigorous human heuristics. For example, on 2019 Day 25 I thought I understood enough of the text adventure to write a program to interact with it, but completely missed the “in-game instruction”:
The standard configuration for these starships is for all droids to weigh exactly the same amount to make them easier to detect. If you need to get past such a sensor, you might be able to reach the correct weight by carrying items from the environment.
This made that day’s puzzle substantially harder for me, because I ended up playing the text adventure “blind” as if I were supposed to figure out the mechanics purely from interacting from it. So I can’t say much more than that there’s a balance to strike in terms of how aggressively you should skim. (And if you do skip the story to leaderboard-race, you should go back and read the story after you finish. It’s pretty entertaining. And don’t forget to admire the front page ASCII art, either.)
Automate as many interactions with the website as you can
We’re getting to the options where you spend potentially hours of prep work to shave seconds off each day’s time. On the other hand, that shaving can be fairly reliable. Basically, for every puzzle you’ll be spending time clicking around, switching windows, and performing other such UI operations. Time spent on those tasks is time that you aren’t using to solve the problem, so the more you can reduce it, the better.
There are a lot of choices for such automation infrastructure to be found on the subreddit and linked from the awesome repo. Personally, the (extremely ugly, unpublished) downloader I hacked together 2018 and 2019 requires no user interaction after midnight to automatically download the input and show me some summary statistics. I can also automatically submit answers from my solution script, but it prompts me y/n right before submitting anything so I can sanity-check the answer and not submit anything I don’t intend.
Edit: As several of the AoC mods commented, if you do go down this route, make sure you don’t repeat any automated queries, or at least rate-limit any such queries, to respect the AoC server! You can and should cache your input after the first time you download it, since it never changes — this is both faster for you and better for the server.Keep improving
To conclude the list, here’s the most open-ended suggestion: After solving each day’s problem, try to reflect on how you could have gone faster. For maximum effect, screen record yourself, then review the recording. What utilities could you have added to your personal library that would have made your life easier? What bugs did you write, and how could you have prevented yourself from writing them or caught them sooner? Looking at other solutions on the reddit megathread, are there any that would have been easier or faster to implement? How could you have come up with them or prepared enough code to write them?
Have fun!
If you pull out all the stops and follow every single suggestion above as far as it’ll take you, you could easily sink a full-time job’s worth of time into preparing for Advent of Code. Most of us aren’t that free,10 so again, only you can decide how much time you think is worth spending on optimizing your Advent of Code runs. Regardless of how you decide to approach Advent of Code, I hope this post was helpful in some way, and if you decide the leaderboard is what you want to aim for, I hope to see you there.
Stay safe and happy coding!